Informatiemodel
Het informatiemodel beschrijft de gegevens die instellingen voor onderwijs en onderzoek beheren. Het wordt ook wel een bedrijfsobjectmodel of een conceptueel gegevensmodel genoemd. Het is nadrukkelijk nog geen logisch gegevensmodel. Het model beschrijft de grotere eenheden van gegevens in een taal die breed in de organisatie herkenbaar is en geeft dus nog geen details over de precieze gegevensstructuur. Het legt focus op bedrijfsobjecten met een grotere verzameling van gestructureerde gegevens die breed worden gedeeld in de organisatie. Het model lijkt op het bedrijfsfunctiemodel in de zin dat het ook onafhankelijk is van de inrichting van organisatie en IT en daardoor ook een stabiel referentiekader biedt. Nog meer dan het bedrijfsfunctiemodel creëert het een gemeenschappelijke taal voor de meest gebruikte objecten waar instellingen mee werken. De namen die voor de bedrijfsobjecten gekozen zijn hebben in de dagelijkse praktijk soms niet een eenduidige betekenis. Het model probeert onduidelijkheden over betekenis te vermijden en bevat daardoor op een aantal plaatsen woorden die minder herkenbaar zijn, maar wel een eenduidige betekenis hebben. Zo is bijvoorbeeld het woord “deelnemer” gekozen in plaats van “student” omdat er in de praktijk allerlei mensen deel kunnen nemen aan het onderwijs die niet volledig te vatten zijn onder de term “student”. Denk daarbij aan prospects (voorbereidend onderwijs), promovendi, extranei en cursisten (postacademisch onderwijs) die aan (een deel van de) onderwijsactiviteiten kunnen deelnemen. We hebben niet geprobeerd al deze (en anderssoortige) rollen uit te modelleren in het informatiemodel. Vanuit het perspectief van het informatiemodel is alleen relevant dat al deze mensen kunnen deelnemen aan het onderwijs.
De toepassing van het informatiemodel ligt vooral in het ondersteunen van organisatiebrede discussies over verantwoordelijkheden voor het beheren van gegevens. In veel instellingen zijn het bronsysteem en het eigenaarschap van gegevens onvoldoende helder aangewezen. Deze onduidelijkheden veroorzaken een lagere kwaliteit van gegevens waardoor het lastig is een consistent en integraal beeld te krijgen. In het kader van verantwoording, die steeds meer aandacht krijgt vanuit de overheid, is dit onacceptabel. Van elk bedrijfsobject zou duidelijk moeten zijn wie eindverantwoordelijk is en wie de gegevens functioneel beheert. Een andere belangrijke toepassing is het bepalen van de applicatie die kan worden beschouwd als bron voor de bij het bedrijfsobject behorende gegevens (ook wel: “system of record”). Hier is verderop in het document een referentiemodel voor beschikbaar. Andere applicaties worden voorzien van gegevens uit de bronapplicatie. Het informatiemodel is ook een hulpmiddel bij het classificeren van gegevens ten behoeve van informatiebeveiliging. In het kader van Cloud computing, Het Nieuwe Werken en Bring Your Own Device vervaagt de grens tussen de instelling en de gebruiker en ontstaan nieuwe beveiligingsrisico’s. Daardoor wordt het belangrijker om zicht te krijgen op welke gegevens meer vertrouwelijk zijn dan andere en welke maatregelen noodzakelijk zijn voor het borgen van integriteit en vertrouwelijkheid.
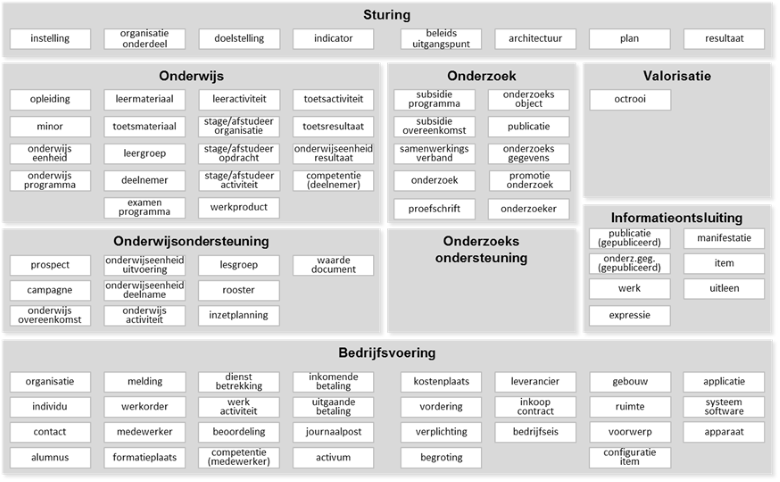
Klik op een van de gebieden in bovenstaand figuur voor meer gedetailleerde informatie. Deze figuur is ook beschikbaar in PDF.
BIV-classificatie
Een BIV-classificatie geeft aan welke mate van beschikbaarheid, integriteit en vertrouwelijkheid gewenst is voor een bepaald gegeven. Het is de basis voor het bepalen van passende informatiebeveiligingsmaatregelen, die op zowel processen, organisatie als technologie impact zullen hebben. Er is in dit project een generieke BIV-classificatie opgesteld. Deze is terug te vinden als een set van attributen bij de bedrijfsobjecten in het informatiemodel en is direct toegankelijk als rapport. Het is aan instellingen zelf om deze generieke BIV-classificatie te vertalen naar hun eigen classificaties en maatregelen. Hiervoor zijn standaard technieken beschikbaar zoals bijvoorbeeld de SPRINT methode voor risico-analyse [12].
Een BIV-classificatie bestaat uit drie scores: een B-score, I-score en V-score. De waardes van deze scores kunnen zijn: hoog, middel of laag. Voor vertrouwelijkheid is er ook een “openbaar” die aangeeft dat specifieke gegevens publiek beschikbaar zijn. Gegevens die een grote rol spelen in de dagelijke operatie van een instelling zijn geclassificeerd met een hogere B-score. Gegevens die nodig zijn voor geplande bijeenkomsten zoals toetsmateriaal scoren de hoogste B-score. De integriteit van sturende en financiële gegevens scoren een verhoogde I score. De gegevens die nodig zijn voor een goede uitvoering van het onderwijs scoren de hoogste I score. De vertrouwelijkheidsscore wordt bepaald door de bedrijfseconomische waarde en door de regelgeving rond de bescherming van persoonsgegevens. Gegevens die de identiteit, nationaliteit of ras vastleggen en gegevens die een economische situatie beschrijven scoren een hogere V-score. Gegevens die de medische, psychische of sociale situatie beschrijven van een persoon krijgen de hoogste V-score.
De V-score wordt in een aantal gevallen sterk beïnvloedt door specifieke attributen. Dit geldt met name voor bedrijfsobjecten met persoonsgegevens doordat de Wet Bescherming Persoonsgegevens allerlei eisen stelt aan vertrouwelijkheid. Het College Bescherming Persoonsgegevens heeft specifieke richtsnoeren opgesteld voor het publiceren van persoonsgegevens op internet [37]. Zuivere persoonsgegevens bevinden zich in de bedrijfsobjecten deelnemer, medewerker en individu. Er zijn bedrijfsobjecten die de relatie tussen de instelling en de personen weergeven. Zo bestaan er rond een deelmer de gevoelige bedrijfsobjecten onderwijsovereenkomst, examenprogramma, onderwijseenheiddeelname, leer- en lesgroep, toetsresultaat en onderwijseenheidresultaat. Dit zijn alle transactiegeoriënteerde gegevenssets met een beperkte set aan attributen. Het heeft geen zin dergelijke bedrijfsobjecten nader te bestuderen op attribuutniveau.
Hieronder is een verkenning gemaakt van de attribuutgroepen die kenmerkend zijn voor de bedrijfsobjecten deelnemer en medewerker. In tabelvorm zijn de attribuutgroepen benoemd en is de bijbehorende V-score weergegeven. In het algemeen geldt, gegevens die van een persoon:
- de identiteit, nationaliteit of ras vastleggen scoren M
- een economische situatie beschrijven scoren M
- de medische, psychische of sociale situatie beschrijven scoren H
| Attribuutgroep | V-score |
|---|---|
| object-id | L |
| DUO-nummer | L |
| onderwijsnummer / BSN | M |
| naamsgegevens | L |
| geslacht | L |
| e-mailadres | L |
| nationaliteit | M |
| verblijfsstatus | M |
| geboortedatum / plaats | M |
| datum / status overlijden | L |
| pasfoto | M |
| adressen (incl. status geheim) | L |
| telefoonnummer(s) (incl. status geheim) | L |
| bankrekeningnummer | M |
| vooropleidingen | L |
| toeganggevens diploma met cijferlijst | L |
| studiegerelateerde communicatie | M |
| functiebeperking | H |
| studie- en deelnemergerelateerde aantekeningen van begeleiders | H |
Tabel 1 V-score voor attribuutgroepen van bedrijfsobject deelnemer
| Attribuutgroep | V-score |
|---|---|
| object-id | L |
| BSN | M |
| naamsgegevens | L |
| geslacht | L |
| burgerlijke staat | L |
| gegevens kinderen | L |
| e-mailadres | L |
| nationaliteit | M |
| werkvergunningsgegevens | M |
| geboortedatum / plaats | M |
| datum / status overlijden | L |
| pasfoto | M |
| kopie paspoort | M |
| adressen (incl. status geheim) | L |
| telefoonnummer(s) (incl. status geheim) | L |
| bankrekeningnummer | M |
| opleidingen met diploma's | L |
| meest relevante diploma | L |
| beperkingen uit religie | M |
| verlof | M |
| ziekteverzuim / arbo-gegevens | H |
| dienstbetrekkinggerelateerde communicatie | M |
| functiebeperking / afspraken daarover | H |
Tabel 2 V-score voor attribuutgroepen van bedrijfsobject medewerker